今日の深層学習の技術を支える要素の一つである教師ラベル付き大規模データセット。その大規模さ故にすべてのデータに対して正しい教師ラベルを付与するのは容易ではなく、一定の割合のラベルミスが存在する。こうしたミスは「学習されたモデルの性能の優劣」の判断を誤らせ、データセットのベンチマークとしての機能の低下を引き起こしかねない。今回紹介する研究では、ラベルミスの悪影響に関する分析を行い、この手の誤りについての関心が低い現在の状況に警鐘を鳴らしている。
教師ラベル付き大規模データセットは今日の深層学習において欠かすことのできない要素の一つだ。自然言語処理における「GPT-3」や画像認識における「Vision Transformer」など、近年話題になったモデルの学習には非常に大規模なデータセットが用いられている。
ところで、一般的に用いられる大規模データセットには、無視できない割合のラベルミスが含まれていることをご存じだろうか? データに正解ラベルを付ける作業は基本的にはクラウドソーシングなどの人力で行われるため、ヒューマンエラーによるラベルミスがある程度含まれてしまう。
これに対して、近年では一定の割合でラベルミスが含まれることを前提とした学習方法などの研究が進み、ラベルの正確さが少々低下することを許容しつつデータセットの大規模さを追求する流れができつつある。
しかしながら、訓練データのラベルミスと同時にテストデータのラベルミスまで軽視してしまうのはいささか早計である。そもそもラベルミスは訓練データとテストデータではその意味が大きく異なる。受験勉強で例えると、訓練データのラベルミスは「参考書の解答のミス」であり、テストデータのラベルミスは「入試問題の解答のミス」である。入試問題の解答ミスが生じた場合、本来正しい解答をした受験生を減点してしまい、「学力を正しく測る」という入試の目的を損ねてしまうので、非常に重大である。機械学習の世界でも重大さは同様であり、テストラベルのミスは「モデルの性能を正しく測る」というベンチマークとしての能力を損ねてしまうことにつながる。テストデータのラベルミスは重大なのだ。
今回取り上げた研究(i)では、重視すべきテストデータのラベルミスがこれまでほとんど注目されてこなかったことを指摘した上で、有名なデータセットではどの程度のミスを含んでいるかを調査し、さらにそれらがどの程度“悪さ”をするのかを検証している。
著名なデータセットのテストラベルミス
最初に、著名なデータセットではどの程度のテストラベルミスが存在しているかを見ていこう。今回検証の対象となったのは図1に示す10種類の分類タスクに関するデータセットである。内訳は画像認識が6種類、自然言語処理が3種類、音声認識が1種類である。
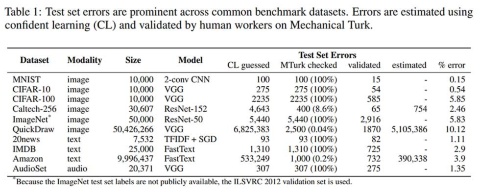
(図1)本研究でテストラベルミスの検証対象となった10種類の分類タスクに関するデータセット。一番左の列にデータセット名、一番右の列にラベルミス率が示されている。出典(i)
このコンテンツ・機能は会員限定です。
- ①2000以上の先進事例を探せるデータベース
- ②未来の出来事を把握し消費を予測「未来消費カレンダー」
- ③日経トレンディ、日経デザイン最新号もデジタルで読める
- ④スキルアップに役立つ最新動画セミナー
からの記事と詳細 ( ベンチマークに悪影響を及ぼすテストデータのラベルミスを検証 - 日経クロストレンド )
https://ift.tt/3tqFvBN
No comments:
Post a Comment